Mi informacion de contacto
Correo[email protected]
2024-07-08
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
La máquina de vectores de soporte (SVM) fue propuesta por primera vez por Corinna Cortés y Vapnik en 1995. Muestra muchas ventajas únicas a la hora de resolver el reconocimiento de patrones de muestras pequeñas, no lineales y de alta dimensión.
Encuentre un hiperplano de clasificación en un espacio de n dimensiones y clasifique los puntos en el espacio. Los puntos en la línea de puntos se denominan máquinas de vectores de soporte Supprot Verctor, y la línea roja en el medio se llama superplano. aumenta la distancia entre todos los puntos y el superplano.
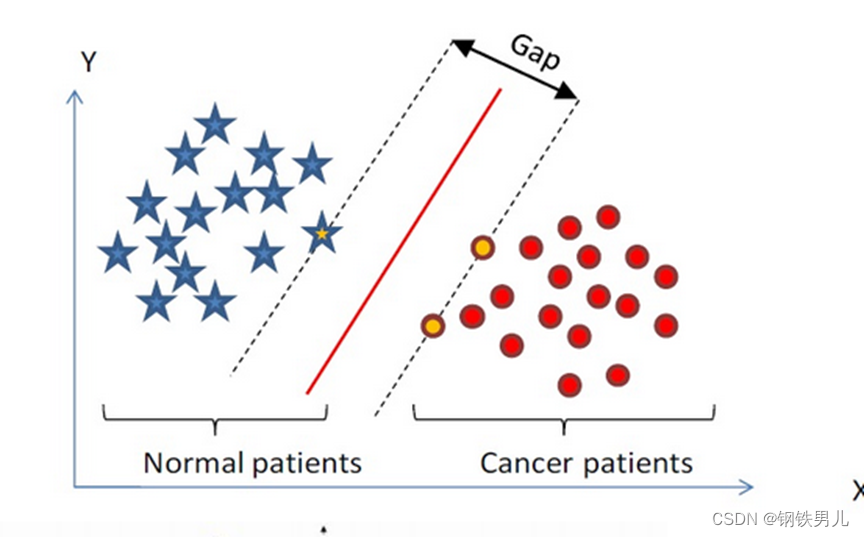
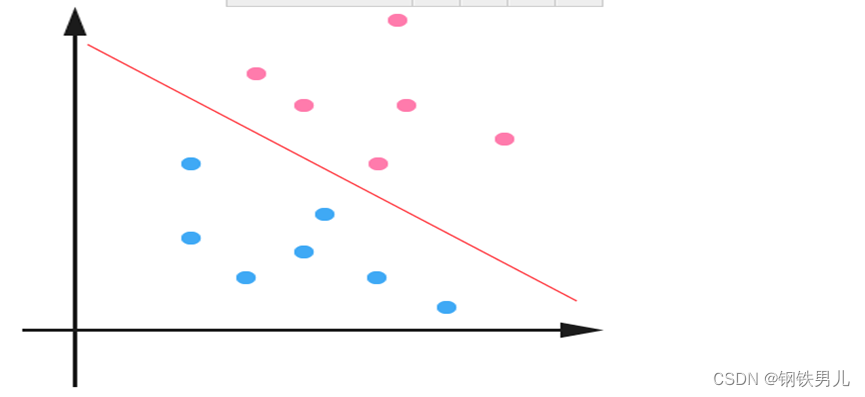
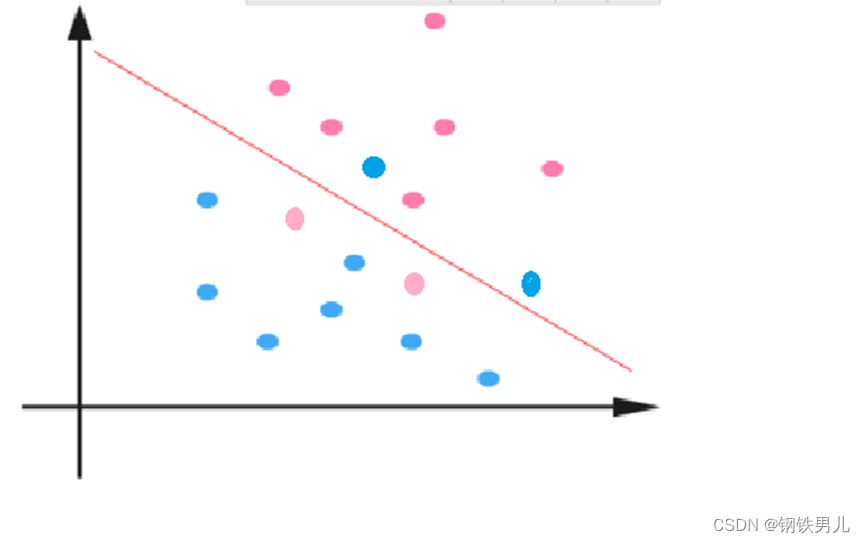
Para situaciones linealmente inseparables, nuestro enfoque común es mapear las características de la muestra en un espacio de alta dimensión.
Sin embargo, el mapeo a un espacio de alta dimensión puede generar dimensiones demasiado grandes y cálculos complicados. Aquí nuevamente se introduce la función del núcleo;
Función kernel: también llamada mapeo no lineal, asigna características de muestra a un espacio de alta dimensión y construye un hiperplano óptimo en este espacio.
Tipos de funciones del kernel: kernel lineal, kernel polinómico, kernel gaussiano (rbf), etc.
Constante regular C: se refiere al grado de restricción del multiplicador de Lagrange en SVM


Cuanto mayor sea el valor de la constante regular, mayor será la penalización, menos tolerante a los errores y más vectores de soporte, lo que fácilmente puede conducir a un sobreajuste.
Por el contrario, cuanto menor sea la constante regular, más fácil será provocar un desajuste.
Uno contra todos (método uno contra todos): durante el entrenamiento, las muestras de una determinada categoría se clasifican en una categoría por turno, y otras muestras restantes se clasifican en otra categoría. De esta manera, se construyen n SVM a partir de n. categorías de muestras.
Uno contra uno (método uno contra uno): durante el entrenamiento, se diseña una SVM entre dos tipos cualesquiera de muestras, por lo que es necesario diseñar n (n-1)/2 SVM para n categorías de muestras.
canonical_variates: análisis de correlación canónica en regresión lineal, utilizamos líneas rectas para ajustar puntos de muestra y encontrar la relación lineal entre el vector de características n-dimensional X y el resultado de salida Y;
Análisis de componentes principales: El análisis de componentes principales (PCA) es un proceso estadístico que utiliza una transformación ortogonal para convertir un conjunto de valores observados de posibles variables correlacionadas en un conjunto de valores de variables linealmente no correlacionadas llamados componentes principales;

Se ha dedicado a la investigación de tecnología durante más de treinta años, domina varios lenguajes como java, linux, javascript, php, css, etc., y ha realizado muchas contribuciones en el campo del código abierto. una estación de documentación para desarrolladores para compartir algunos problemas en el desarrollo de tecnología para referencia futura.

Correo[email protected]