le mie informazioni di contatto
Posta[email protected]
2024-07-08
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Support Vector Machine (SVM) è stata proposta per la prima volta da Corinna Cortes e Vapnik nel 1995. Mostra molti vantaggi unici nella risoluzione del riconoscimento di modelli di piccoli campioni, non lineari e ad alta dimensione.
Trova un iperpiano di classificazione nello spazio n-dimensionale e classifica i punti nello spazio. I punti sulla linea tratteggiata sono chiamati macchine vettoriali di supporto Supprot Verctor e la linea rossa al centro è chiamata super piano aumentare la distanza tra tutti i punti e il superpiano.
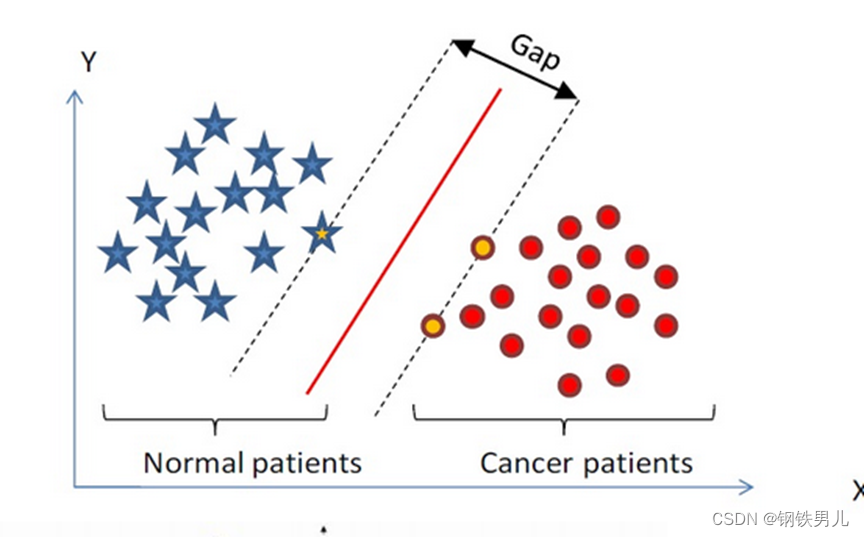
Per situazioni linearmente inseparabili, il nostro approccio comune è quello di mappare le caratteristiche del campione in uno spazio ad alta dimensione.
Tuttavia, la mappatura su uno spazio ad alta dimensionalità può comportare dimensioni troppo grandi e calcoli complicati. Anche qui viene introdotta la funzione kernel;
Funzione kernel: chiamata anche mappatura non lineare, mappa le caratteristiche del campione in uno spazio ad alta dimensione e costruisce un iperpiano ottimale in questo spazio.
Tipi di funzioni del kernel: kernel lineare, kernel polinomiale, kernel gaussiano (rbf), ecc.
Costante regolare C: si riferisce al grado di vincolo del moltiplicatore di Lagrange in SVM


Maggiore è il valore della costante regolare, maggiore è la penalità, minore è la tolleranza agli errori e maggiori sono i vettori di supporto, che possono facilmente portare a un overfitting.
Al contrario, quanto più piccola è la costante regolare, tanto più facile è causare un underfitting.
uno contro tutti (metodo uno contro tutti): durante l'addestramento, i campioni di una determinata categoria vengono classificati a turno in una categoria e gli altri campioni rimanenti vengono classificati in un'altra categoria. In questo modo, n SVM vengono costruite da n categorie di campioni.
Uno contro uno (metodo uno contro uno): durante l'addestramento, una SVM viene progettata tra due tipi di campioni qualsiasi, quindi n (n-1)/2 SVM devono essere progettate per n categorie di campioni.
canonical_variates: analisi della correlazione canonica. Nella regressione lineare, utilizziamo linee rette per adattare i punti campione e trovare la relazione lineare tra il vettore di caratteristiche n-dimensionali X e il risultato di output Y;
Analisi delle componenti principali: L'analisi delle componenti principali (PCA) è un processo statistico che utilizza una trasformazione ortogonale per convertire un insieme di valori osservati di possibili variabili correlate in un insieme di valori di variabili linearmente non correlate chiamate componenti principali;

Si dedica alla ricerca tecnologica da più di 30 anni ed è esperto in vari linguaggi come Java, Linux, Javascript, php, css, ecc. Ha dato numerosi contributi nel campo dell'open source stazione di documentazione per gli sviluppatori per condividere alcuni problemi nello sviluppo della tecnologia per riferimento futuro

Posta[email protected]