моя контактная информация
Почтамезофия@protonmail.com
2024-07-08
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Машина опорных векторов (SVM) была впервые предложена Коринной Кортес и Вапником в 1995 году. Она демонстрирует множество уникальных преимуществ при решении задач распознавания образов на небольших выборках, нелинейных и многомерных задачах.
Найдите гиперплоскость классификации в n-мерном пространстве и классифицируйте точки в пространстве. Точки на пунктирной линии называются машинами опорных векторов, а красная линия в середине называется суперплоскостью. увеличьте расстояние между всеми точками и суперплоскостью.
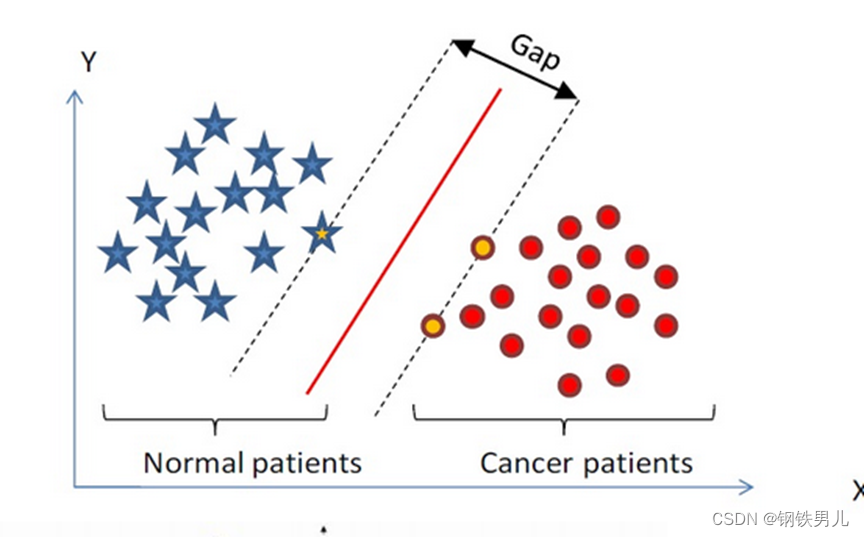
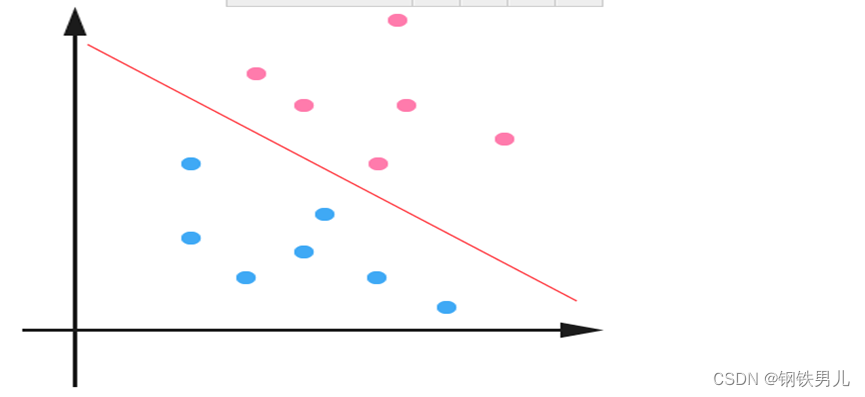
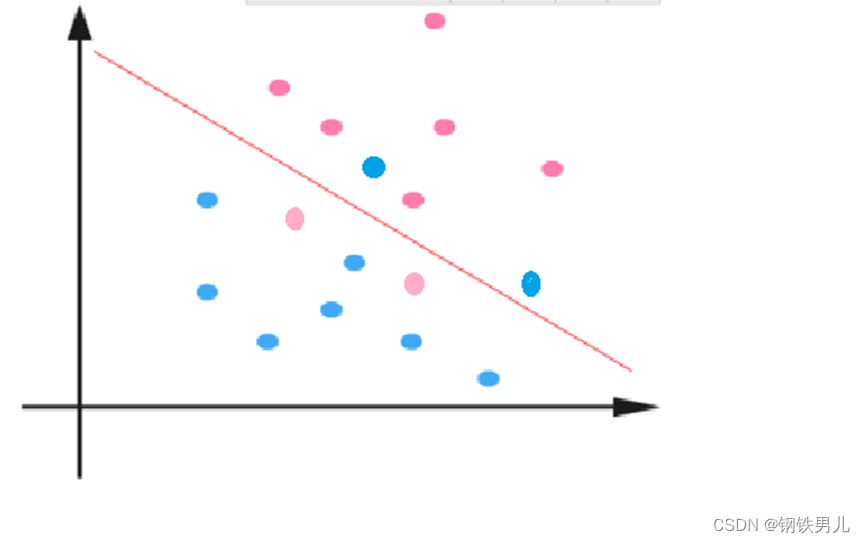
Для линейно неразделимых ситуаций наш общий подход состоит в том, чтобы отобразить выборочные функции в многомерном пространстве.
Однако отображение в многомерном пространстве может привести к слишком большим размерам и сложным вычислениям. Здесь снова вводится функция ядра;
Функция ядра: также называемая нелинейным отображением. Она отображает выборочные объекты в многомерное пространство и строит в этом пространстве оптимальную гиперплоскость.
Типы функций ядра: линейное ядро, полиномиальное ядро, ядро Гаусса (rbf) и т. д.
Обычная константа C: относится к степени ограничения множителя Лагранжа в SVM.


Чем больше значение регулярной константы, тем больше штраф, тем менее толерантно к ошибкам, тем больше опорных векторов, что легко может привести к переобучению.
Напротив, чем меньше регулярная константа, тем легче вызвать недооснащение.
«один против всех» (метод «один против всех»). Во время обучения выборки определенной категории по очереди классифицируются в одну категорию, а остальные оставшиеся выборки классифицируются в другую категорию. Таким образом, n SVM создаются из n. категории образцов.
«Один против одного» (метод «один против одного»). Во время обучения SVM разрабатывается для любых двух типов выборок, поэтому необходимо разработать n (n-1)/2 SVM для n категорий выборок.
canonical_variates: канонический корреляционный анализ. В линейной регрессии мы используем прямые линии для подбора точек выборки и находим линейную связь между n-мерным вектором признаков X и выходным результатом Y;
Анализ главных компонентов: Анализ главных компонентов (PCA) — это статистический процесс, который использует ортогональное преобразование для преобразования набора наблюдаемых значений возможных коррелирующих переменных в набор значений линейно некоррелированных переменных, называемых главными компонентами;

Он посвятил себя исследованию технологий более 30 лет и владеет различными языками, такими как Java, Linux, Javascript, php, css и т. д. Он внес большой вклад в область открытого исходного кода. Станция документации для разработчиков, где можно поделиться некоторыми проблемами в разработке технологий для дальнейшего использования.

Почтамезофия@protonmail.com