2024-07-08
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Support Vector Machine (SVM) wurde erstmals 1995 von Corinna Cortes und Vapnik vorgeschlagen. Es zeigt viele einzigartige Vorteile bei der Lösung kleiner Stichproben, nichtlinearer und hochdimensionaler Mustererkennung.
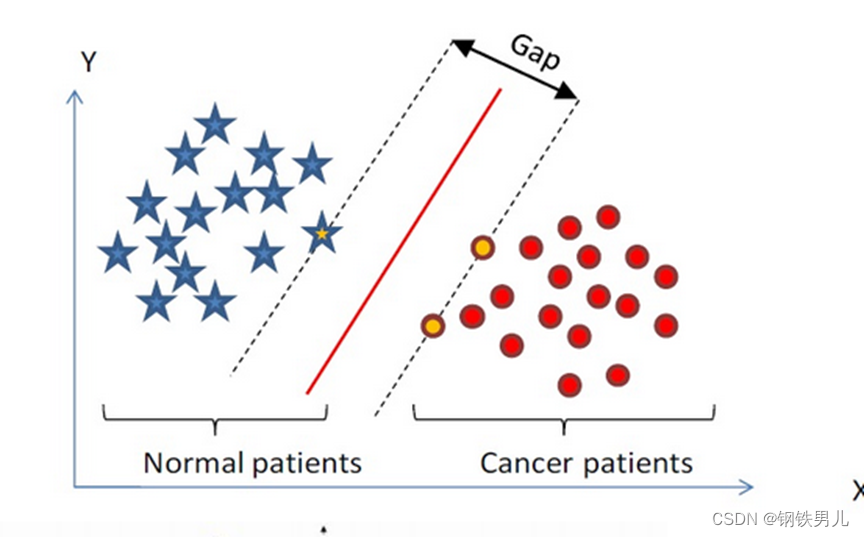
Finden Sie eine Klassifizierungshyperebene im n-dimensionalen Raum und klassifizieren Sie die Punkte im Raum. Die Punkte auf der gepunkteten Linie werden als Support Vector Machines Supprot Verctor bezeichnet, und die rote Linie in der Mitte wird als Superebene bezeichnet Erhöhen Sie den Abstand zwischen allen Punkten und der Superebene.
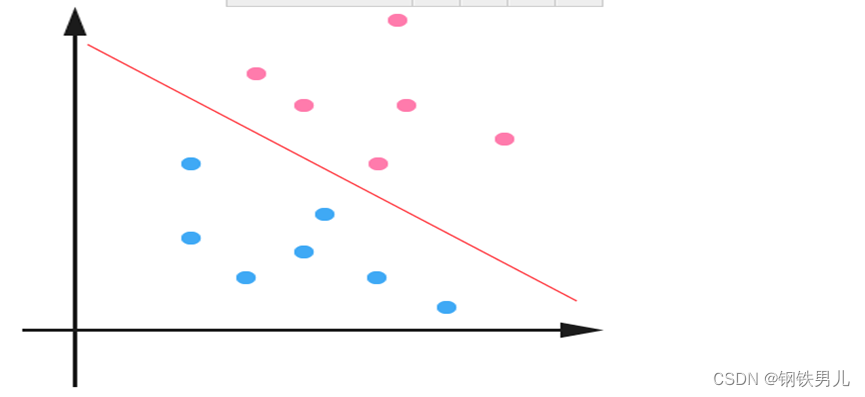
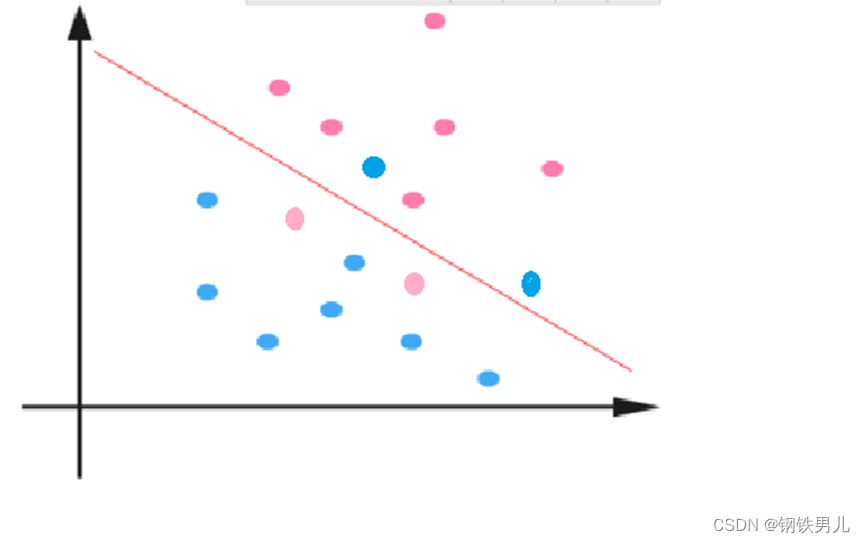
Für linear untrennbare Situationen besteht unser gemeinsamer Ansatz darin, die Beispielmerkmale in einen hochdimensionalen Raum abzubilden.
Die Abbildung auf einen hochdimensionalen Raum kann jedoch zu zu großen Dimensionen und komplizierten Berechnungen führen. Auch hier wird die Kernelfunktion vorgestellt;
Kernelfunktion: Auch als nichtlineare Zuordnung bezeichnet. Sie ordnet Beispielmerkmale einem hochdimensionalen Raum zu und konstruiert in diesem Raum eine optimale Hyperebene.
Kernel-Funktionstypen: linearer Kernel, Polynomkernel, Gaußscher Kernel (rbf) usw.
Regelmäßige Konstante C: bezieht sich auf den Grad der Einschränkung des Lagrange-Multiplikators in SVM


Je größer der Wert der regulären Konstante, desto größer die Strafe, desto geringer die Fehlertoleranz und desto mehr Unterstützungsvektoren, was leicht zu einer Überanpassung führen kann.
Im Gegenteil: Je kleiner die reguläre Konstante ist, desto leichter kann es zu einer Unteranpassung kommen.
Eins-gegen-Alle (Eins-gegen-Alle-Methode): Während des Trainings werden Proben einer bestimmten Kategorie der Reihe nach in eine Kategorie eingeteilt, und andere verbleibende Proben werden in eine andere Kategorie eingeteilt. Auf diese Weise werden n SVMs aus n erstellt Kategorien von Proben.
Eins-gegen-eins (Eins-gegen-eins-Methode): Während des Trainings wird eine SVM zwischen zwei beliebigen Probentypen entworfen, sodass n (n-1)/2 SVMs für n Kategorien von Proben entworfen werden müssen.
canonical_variates: Kanonische Korrelationsanalyse. Bei der linearen Regression verwenden wir gerade Linien, um Stichprobenpunkte anzupassen und die lineare Beziehung zwischen dem n-dimensionalen Merkmalsvektor X und dem Ausgabeergebnis Y zu ermitteln.
Hauptkomponentenanalyse: Die Hauptkomponentenanalyse (PCA) ist ein statistischer Prozess, der eine orthogonale Transformation verwendet, um eine Reihe beobachteter Werte möglicher korrelierter Variablen in eine Reihe von Werten linear unkorrelierter Variablen, die als Hauptkomponenten bezeichnet werden, umzuwandeln.

Er widmet sich seit mehr als 30 Jahren der Technologieforschung und beherrscht verschiedene Sprachen wie Java, Linux, Javascript, PHP, CSS usw. Er hat viele Beiträge im Open-Source-Bereich geleistet Entwicklerdokumentationsstation, um einige Themen in der Technologieentwicklung als zukünftige Referenz zu teilen
