informasi kontak saya
Surat[email protected]
2024-07-08
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Support Vector Machine (SVM) pertama kali diusulkan oleh Corinna Cortes dan Vapnik pada tahun 1995. Ini menunjukkan banyak keuntungan unik dalam menyelesaikan pengenalan pola sampel kecil, nonlinier, dan dimensi tinggi.
Temukan hyperplane klasifikasi dalam ruang berdimensi n dan klasifikasikan titik-titik dalam ruang tersebut. Titik-titik pada garis putus-putus disebut mesin vektor pendukung Supprot Verctor, dan garis merah di tengahnya disebut bidang super menambah jarak antara semua titik dan bidang super.
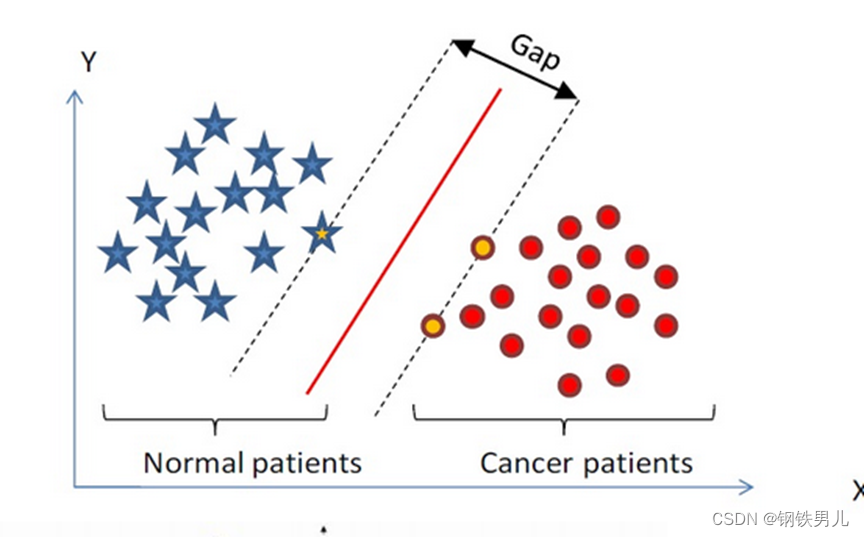
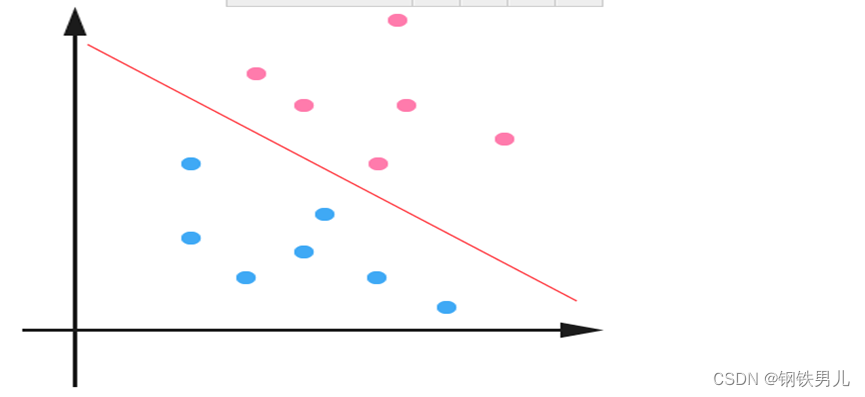
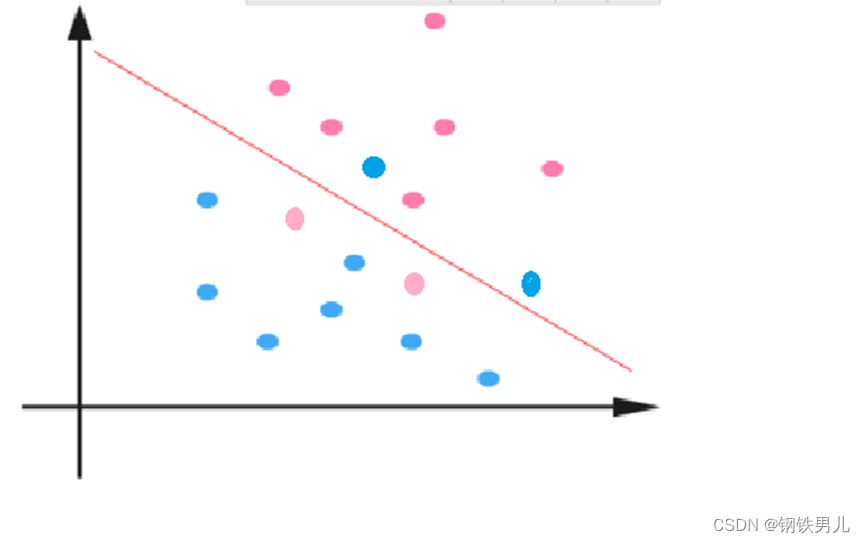
Untuk situasi yang tidak dapat dipisahkan secara linier, pendekatan umum kami adalah memetakan fitur sampel ke dalam ruang berdimensi tinggi.
Namun, pemetaan ke ruang berdimensi tinggi dapat mengakibatkan dimensi yang terlalu besar dan perhitungan yang rumit. Di sini sekali lagi fungsi kernel diperkenalkan;
Fungsi kernel: Disebut juga pemetaan nonlinier, memetakan fitur sampel ke ruang berdimensi tinggi dan membangun hyperplane optimal di ruang ini.
Jenis fungsi kernel: kernel linier, kernel polinomial, kernel Gaussian (rbf), dll.
Konstanta reguler C: mengacu pada tingkat batasan pengali Lagrange di SVM


Semakin besar nilai konstanta reguler, semakin besar penaltinya, semakin sedikit toleransi terhadap kesalahan, semakin banyak vektor dukungan, yang dapat dengan mudah menyebabkan overfitting.
Sebaliknya, semakin kecil konstanta regulernya, semakin mudah menyebabkan underfitting.
satu lawan semua (metode satu lawan semua): Selama pelatihan, sampel dari kategori tertentu diklasifikasikan ke dalam satu kategori secara bergantian, dan sampel lainnya diklasifikasikan ke dalam kategori lain. Dengan cara ini, n SVM dibangun dari n kategori sampel.
Satu lawan satu (metode satu lawan satu): Selama pelatihan, SVM dirancang antara dua jenis sampel apa pun, jadi n (n-1)/2 SVM perlu dirancang untuk n kategori sampel.
canonical_variates: analisis korelasi kanonik. Dalam regresi linier, kami menggunakan garis lurus untuk menyesuaikan titik sampel dan menemukan hubungan linier antara vektor fitur n-dimensi X dan hasil keluaran Y;
Analisis komponen utama: Analisis komponen utama (PCA) adalah proses statistik yang menggunakan transformasi ortogonal untuk mengubah sekumpulan nilai observasi dari kemungkinan variabel berkorelasi menjadi sekumpulan nilai variabel tidak berkorelasi linier yang disebut komponen utama;

Ia telah mengabdikan dirinya untuk meneliti teknologi selama lebih dari tiga puluh tahun, dan mahir dalam berbagai bahasa seperti java, linux, javascript, php, css, dll, dan telah memberikan banyak kontribusi di bidang open source yang telah ia dirikan stasiun dokumentasi pengembang untuk berbagi beberapa masalah dalam pengembangan teknologi untuk referensi di masa mendatang

Surat[email protected]