2024-07-08
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
La machine à vecteurs de support (SVM) a été proposée pour la première fois par Corinna Cortes et Vapnik en 1995. Elle présente de nombreux avantages uniques dans la résolution de la reconnaissance de formes de petits échantillons, non linéaires et de grande dimension.
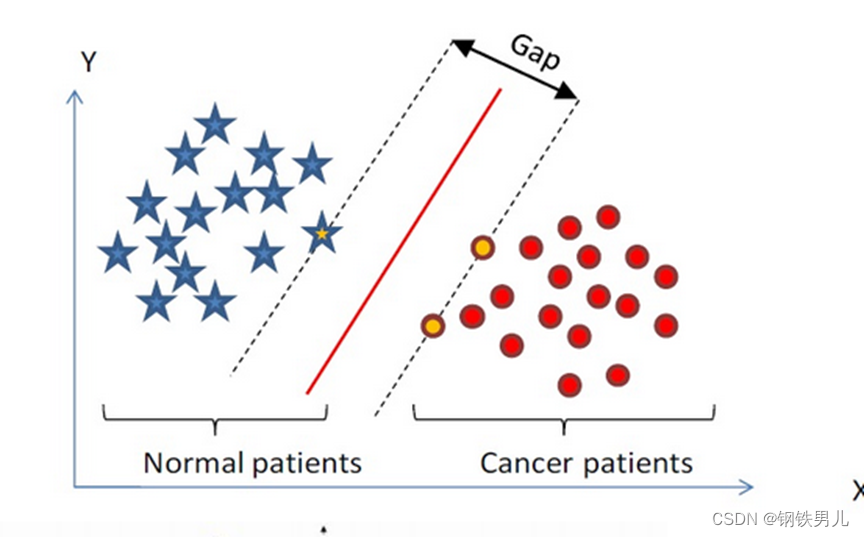
Trouvez un hyperplan de classification dans un espace à n dimensions et classez les points dans l'espace. Les points sur la ligne pointillée sont appelés machines à vecteurs de support Supprot Verctor, et la ligne rouge au milieu est appelée le super plan. augmentez la distance entre tous les points et le super avion.
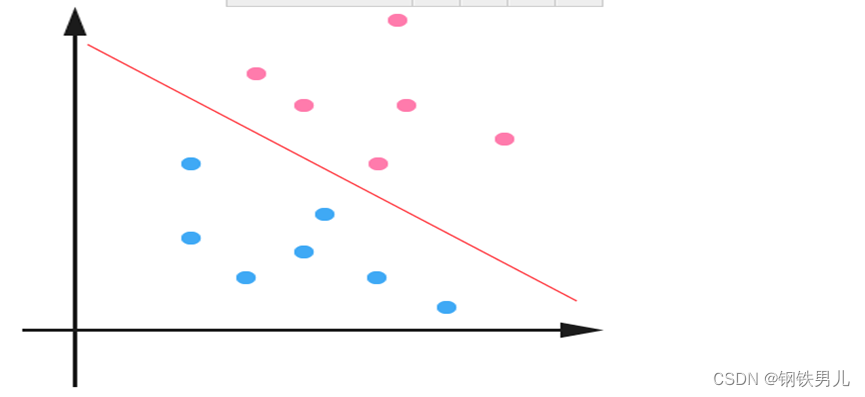
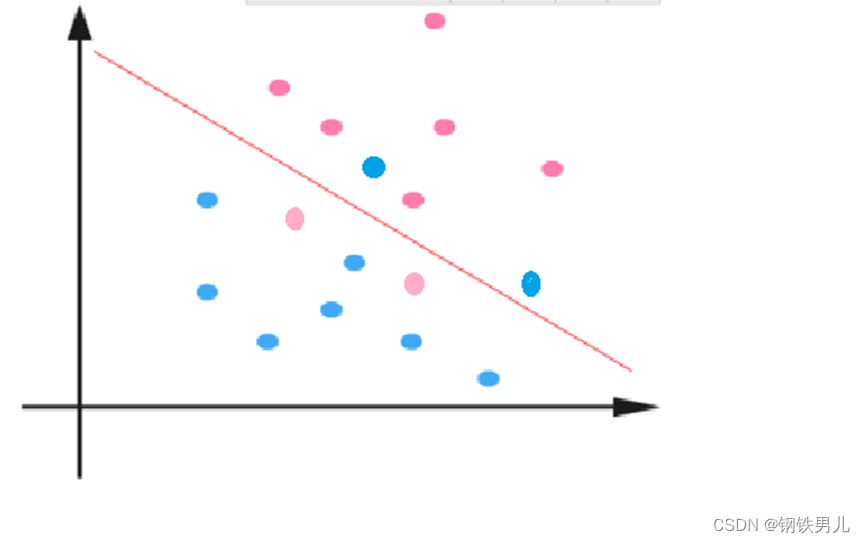
Pour les situations linéairement inséparables, notre approche courante consiste à mapper les exemples d’entités dans un espace de grande dimension.
Cependant, le mappage vers un espace de grande dimension peut entraîner des dimensions trop grandes et des calculs compliqués. Ici encore, la fonction noyau est introduite ;
Fonction noyau : également appelée cartographie non linéaire, elle mappe des exemples d'entités sur un espace de grande dimension et construit un hyperplan optimal dans cet espace.
Types de fonctions du noyau : noyau linéaire, noyau polynomial, noyau gaussien (rbf), etc.
Constante régulière C : fait référence au degré de contrainte du multiplicateur de Lagrange dans SVM


Plus la valeur de la constante régulière est grande, plus la pénalité est grande, moins les erreurs sont tolérantes, plus il y a de vecteurs de support, ce qui peut facilement conduire à un surajustement.
Au contraire, plus la constante régulière est petite, plus il est facile de provoquer un sous-ajustement.
un contre tous (méthode un contre tous) : pendant la formation, les échantillons d'une certaine catégorie sont classés à leur tour dans une catégorie, et les autres échantillons restants sont classés dans une autre catégorie. De cette manière, n SVM sont construits à partir de n. catégories d’échantillons.
Un contre un (méthode un contre un) : pendant la formation, un SVM est conçu entre deux types d'échantillons quelconques, donc n (n-1)/2 SVM doivent être conçus pour n catégories d'échantillons.
canonical_variates : analyse de corrélation canonique. Dans la régression linéaire, nous utilisons des lignes droites pour ajuster des points d'échantillonnage et trouver la relation linéaire entre le vecteur de caractéristiques à n dimensions X et le résultat de sortie Y ;
Analyse en composantes principales : L'analyse en composantes principales (ACP) est un processus statistique qui utilise une transformation orthogonale pour convertir un ensemble de valeurs observées de variables corrélées possibles en un ensemble de valeurs de variables linéairement non corrélées appelées composantes principales ;

Il se consacre à la recherche technologique depuis plus de trente ans, maîtrise divers langages tels que java, linux, javascript, php, css, etc., et a apporté de nombreuses contributions dans le domaine de l'open source. une station de documentation pour les développeurs pour partager certains problèmes de développement technologique pour référence future.
