minhas informações de contato
Correspondência[email protected]
2024-07-08
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
A Support Vector Machine (SVM) foi proposta pela primeira vez por Corinna Cortes e Vapnik em 1995. Ela mostra muitas vantagens exclusivas na solução de reconhecimento de amostras pequenas, não lineares e de padrões de alta dimensão.
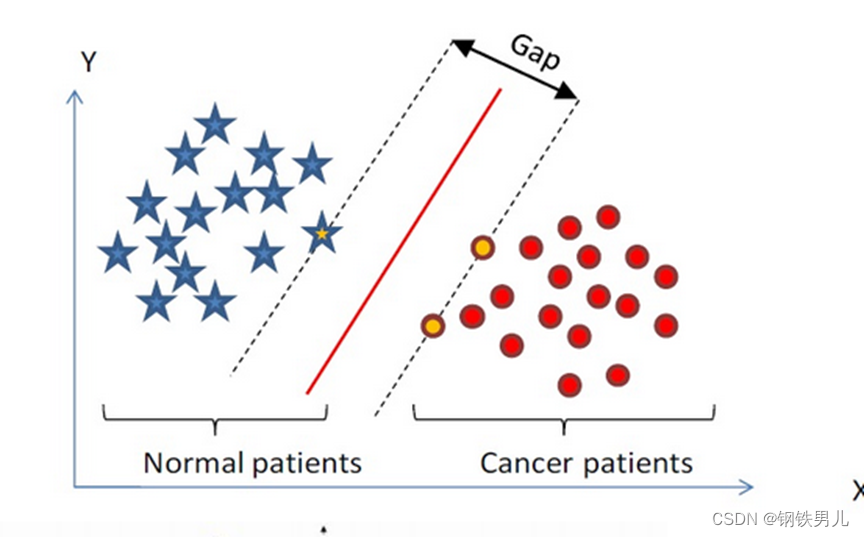
Encontre um hiperplano de classificação no espaço n-dimensional e classifique os pontos no espaço. Os pontos na linha pontilhada são chamados de máquinas de vetores de suporte Supprot Verctor, e a linha vermelha no meio é chamada de superplano. aumente a distância entre todos os pontos e o superplano.
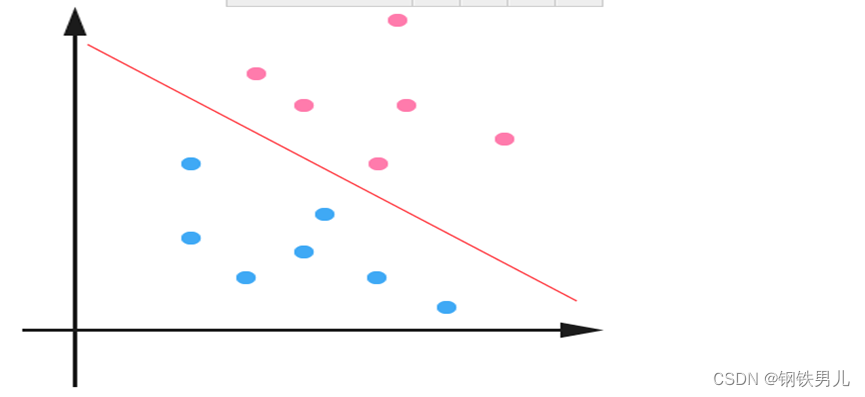
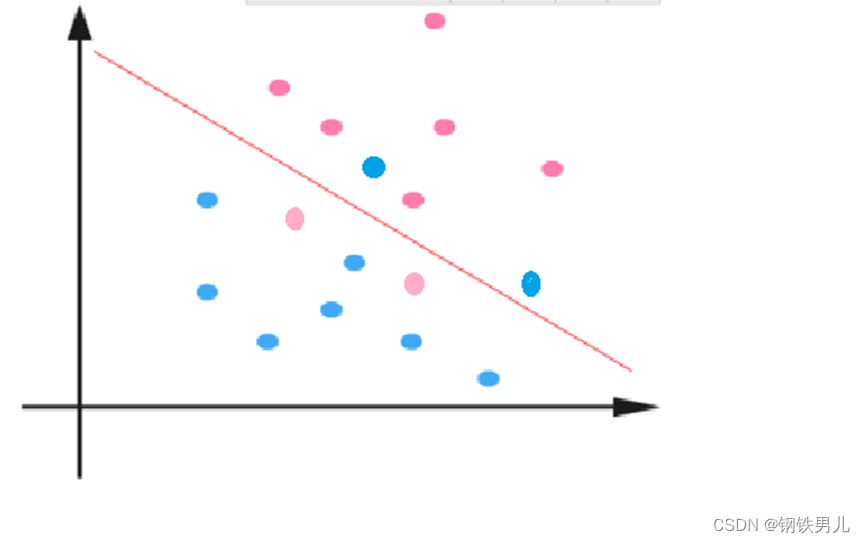
Para situações linearmente inseparáveis, nossa abordagem comum é mapear as características da amostra em um espaço de alta dimensão.
No entanto, o mapeamento para um espaço de alta dimensão pode resultar em dimensões muito grandes e cálculos complicados. Aqui novamente a função kernel é introduzida;
Função Kernel: Também chamada de mapeamento não linear, ela mapeia recursos de amostra para um espaço de alta dimensão e constrói um hiperplano ideal neste espaço.
Tipos de função do kernel: kernel linear, kernel polinomial, kernel gaussiano (rbf), etc.
Constante regular C: refere-se ao grau de restrição do multiplicador de Lagrange no SVM


Quanto maior o valor da constante regular, maior a penalidade, menos tolerante a erros e mais vetores de suporte, o que pode facilmente levar ao sobreajuste.
Pelo contrário, quanto menor for a constante regular, mais fácil será causar subajuste.
um contra todos (método um contra todos): Durante o treinamento, amostras de uma determinada categoria são classificadas em uma categoria por vez, e outras amostras restantes são classificadas em outra categoria, n SVMs são construídos a partir de n. categorias de amostras.
Um contra um (método um contra um): Durante o treinamento, um SVM é projetado entre quaisquer dois tipos de amostras, portanto, n (n-1)/2 SVMs precisam ser projetados para n categorias de amostras.
canonical_variates: análise de correlação canônica Na regressão linear, usamos linhas retas para ajustar os pontos de amostra e encontrar a relação linear entre o vetor de características n-dimensional X e o resultado de saída Y;
Análise de componentes principais: A análise de componentes principais (PCA) é um processo estatístico que utiliza uma transformação ortogonal para converter um conjunto de valores observados de possíveis variáveis correlacionadas em um conjunto de valores de variáveis linearmente não correlacionadas chamadas componentes principais;

Ele se dedica à pesquisa de tecnologia há mais de 30 anos e é proficiente em diversas linguagens como java, linux, javascript, php, css, etc. estação de documentação do desenvolvedor para compartilhar alguns problemas no desenvolvimento de tecnologia para referência futura.

Correspondência[email protected]