2024-07-08
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Corinna Cortes ja Vapnik ehdottivat tukivektorikonetta (SVM) ensimmäisen kerran vuonna 1995. Sillä on monia ainutlaatuisia etuja pienten näytteiden, epälineaarisen ja korkeadimensionaalisen kuviontunnistuksen ratkaisemisessa.
Etsi luokittelun hypertaso n-ulotteisesta avaruudesta ja luokittele avaruuden pisteet katkoviivalla olevia pisteitä kutsutaan tukivektorikoneiksi, ja keskellä olevaa punaista viivaa kutsutaan supertasoksi lisää etäisyyttä kaikkien pisteiden ja supertason välillä.
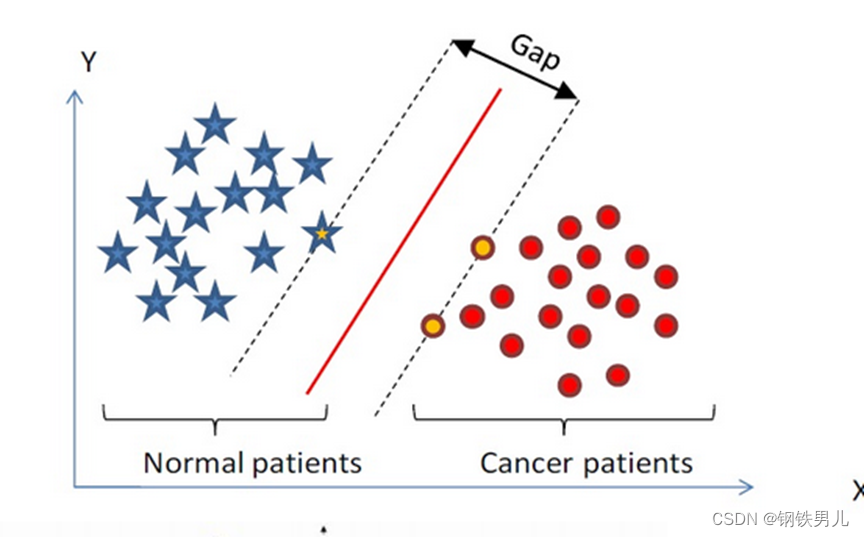
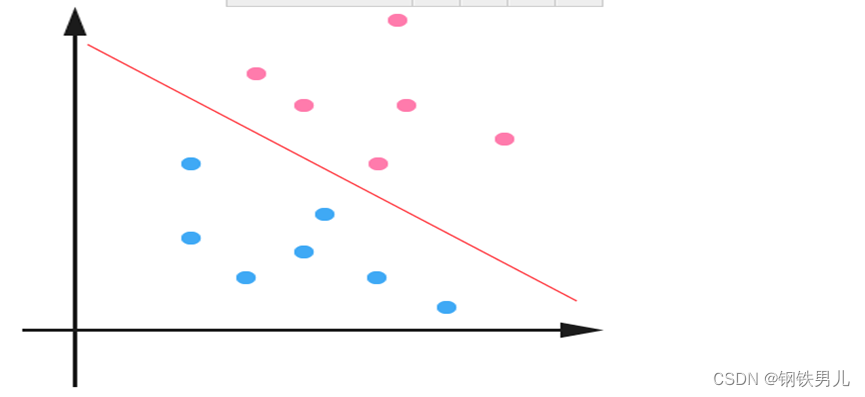
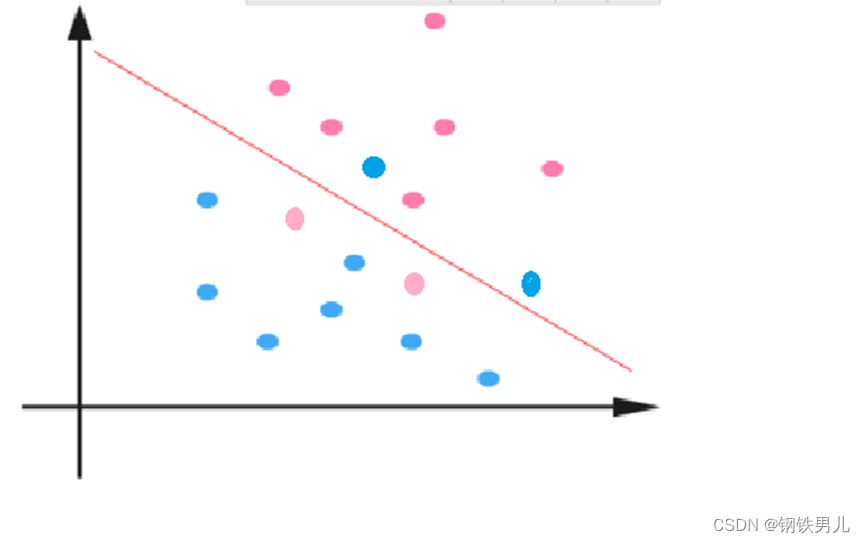
Lineaarisesti erottamattomissa tilanteissa yleinen lähestymistapamme on kartoittaa näyteominaisuudet korkeaulotteiseen avaruuteen.
Kuitenkin kartoitus suuriulotteiseen tilaan voi johtaa liian suuriin mittoihin ja monimutkaisiin laskelmiin. Tässä taas esitellään ydinfunktio;
Ydinfunktio: Kutsutaan myös epälineaariseksi mappaukseksi, se kartoittaa näytepiirteet korkeadimensionaaliseen avaruuteen ja rakentaa optimaalisen hypertason tähän avaruuteen.
Ytimen funktiotyypit: lineaarinen ydin, polynomiydin, Gaussin ydin (rbf) jne.
Säännöllinen vakio C: viittaa Lagrange-kertoimen rajoitusasteeseen SVM:ssä


Mitä suurempi säännöllisen vakion arvo, sitä suurempi sakko, sitä vähemmän sietää virheitä, sitä enemmän tukivektoreita, mikä voi helposti johtaa ylisovitukseen.
Päinvastoin, mitä pienempi säännöllinen vakio on, sitä helpompi on aiheuttaa alasovitusta.
yksi vastaan-kaikki (yksi vastaan kaikki -menetelmä): Harjoittelun aikana tietyn luokan näytteet luokitellaan vuorotellen yhteen luokkaan ja muut jäljellä olevat näytteet toiseen luokkaan. Tällä tavalla muodostetaan n SVM:tä näytteiden luokat.
Yksi vastaan yksi (yksi vastaan yksi -menetelmä): Harjoittelun aikana SVM suunnitellaan minkä tahansa kahden tyyppisen näytteen väliin, joten n (n-1)/2 SVM:ää on suunniteltava n näytekategorialle.
canonical_variates: kanoninen korrelaatioanalyysi Lineaarisessa regressiossa käytämme suoria viivoja sovittamaan näytepisteet ja etsimään lineaarisen suhteen n-ulotteisen piirrevektorin X ja tulostuloksen Y välillä.
Pääkomponenttianalyysi: Pääkomponenttianalyysi (PCA) on tilastollinen prosessi, joka käyttää ortogonaalista muunnosta mahdollisten korreloitujen muuttujien havaittujen arvojen joukoksi lineaarisesti korreloimattomien muuttujien, joita kutsutaan pääkomponenteiksi, arvojoukoksi;

Hän on omistautunut teknologian tutkimukselle yli kolmenkymmenen vuoden ajan ja hallitsee useita kieliä, kuten java, linux, javascript, php, css jne., ja hän on tehnyt monia panoksia avoimen lähdekoodin alalla Kehittäjän dokumentaatioasema, jossa voit jakaa joitakin teknologian kehittämisen ongelmia tulevaa käyttöä varten
